
What I've learned designing data systems
Notes on data system design, IFTT data architectures and functional data engineering
Last week I ran a poll on this newsletter and on LinkedIn to see what type of content you most want to see from me. The answer did not surprise me :) I’ve been trying to balance analytics and engineering content since I started this newsletter.
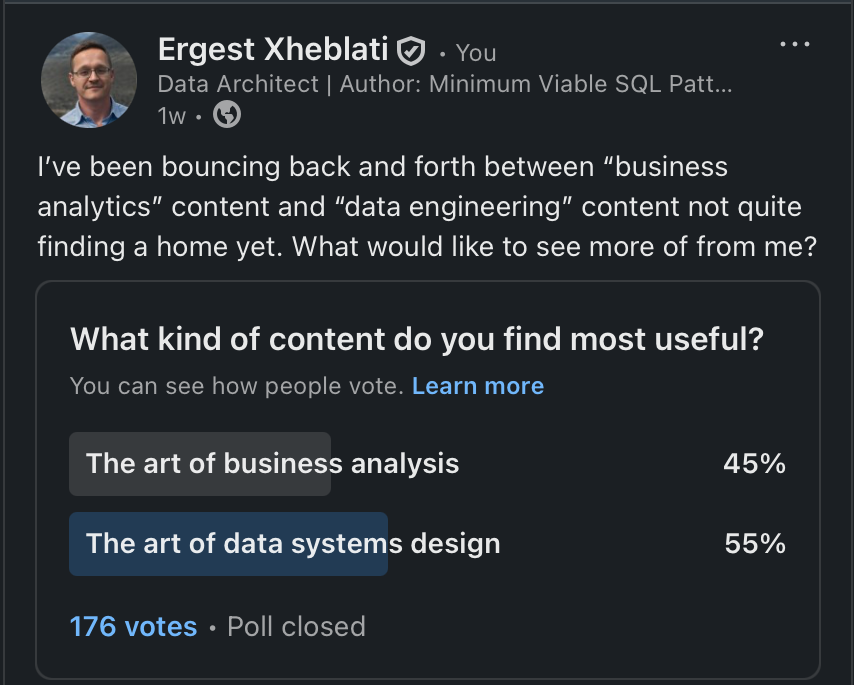
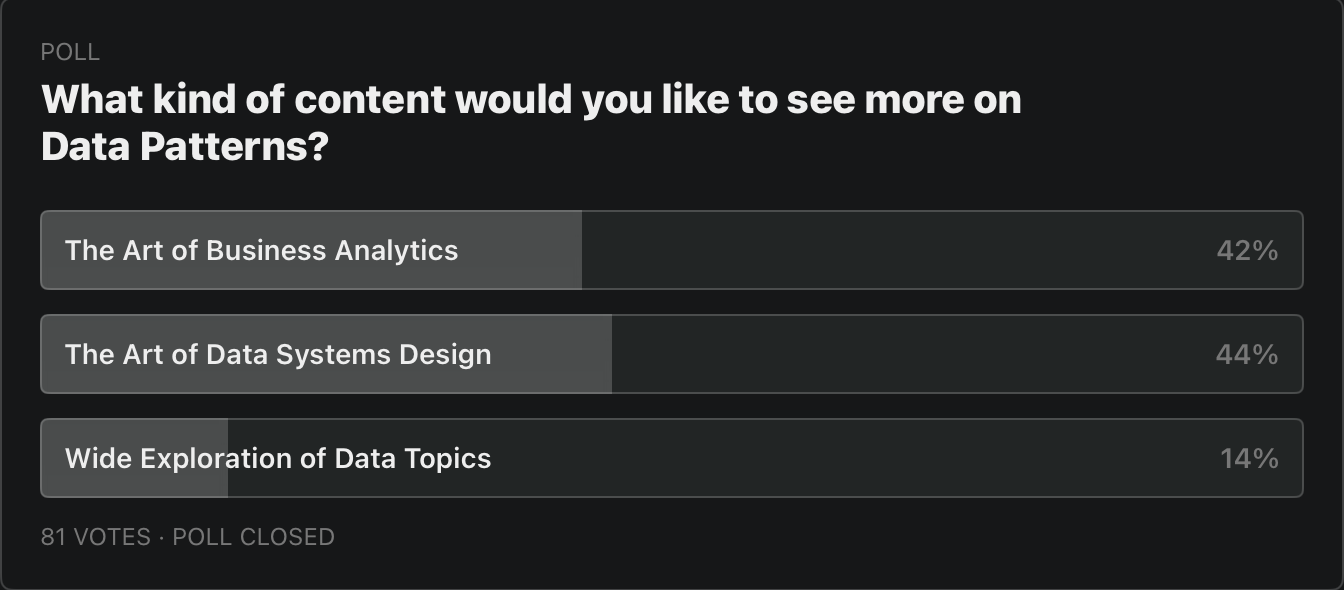
And while the system design won, what this says to me is that I have to continue to straddle the line between analytics and engineering, so don’t fret. I will alternate posts between the two.
This week’s post is about data system design.
I’ve been designing data systems throughout my career. It started out building data warehouses on SQL Server using SSIS and stored procedures and continued onto cloud data platforms (BigQuery then Snowflake). Nowadays it’s mostly PostgreSQL (dbt) and some Python.
Here’s what I’ve learned:
You can’t know all the requirements upfront
My entire career, the one thing that has remained constant is how requirements keep changing as business needs evolve. This has made very apparent for me the need for a modular design.
I covered modularity in my book Minimum Viable SQL Patterns, but that was in the context of SQL queries. Modularity is actually a system design pattern. The key is simple, self-contained components that can be reasoned about, developed and tested independently.
A simple, evolvable architecture is crucial
The traditional way systems are designed is to gather all requirements and then spend time designing the perfect system. This is known as BDUF (big design upfront). I’ve often found that even if I know (or think I know) the requirements, I have a really hard time designing a large system upfront.
Some people have the ability to design the whole thing in their heads. That’s not me. In fact, I prefer to get started with a minimal design, where I outline the various elements of data transformation (simple boxes and arrows design) then I just start coding. This way I can evolve the system as I go.
Design the data model first
When starting to design a data system (like a data warehouse) one of the key elements that MUST be designed upfront is the data model. Like the rest of the system it needs to be easy to evolve and maintain, but once you’ve got something drawn up, it dictates the rest of the elements.
How you model data depends on what you want to do with it. If you want to analyze business processes, model events and activities using facts and dimensions. Kimball is great for that. Start with one-big-table and evolve as needed. If you want to analyze entities (e.g. customers, campaigns) model entities directly and roll up the activities and metrics to the entity level.
I plan to write a much more in-depth article on entity-centric modeling so stay tuned.
Articles I’ve been reading
Going forward, I’ll be including a section with relevant articles based on the theme of each post. This week you get some links on functional data engineering
FITT Data Architecture
Functional, Idempotent, Tested, Two-stage (FITT) data architecture has saved our sanity—no more 3 AM pipeline debugging sessions.
A wonderful article by Chris Bergh of DataKitchen explaining why a functional approach to data engineering can save you a lot of headaches in the long run. My favorite quote:
Yes, storage and compute have costs, but debugging at 2 AM is infinitely more expensive. The math is simple: data engineering time is worth more than compute costs, which are worth more than storage costs.
FITT vs. Fragile: SQL & Orchestration Techniques For FITT Data Architectures
SQL & Orchestration Techniques For Functional, Idempotent, Tested, Two-Stage Data Architectures
Another banger by Chris Bergh, and a follow up to the above article. What I love about this article is that Chris gets into the weeds of how to make SQL — a language decidedly designed for state mutations — be more functional.
Idempotence in SQL requires even more deliberate design. The naive approach of simply re-running transformation queries often fails because SQL operations like INSERT, UPDATE, and DELETE are inherently stateful.
Functional Data Engineering — a modern paradigm for batch data processing
The grandaddy of functional data engineering articles by Max Beauchemin which lays out the critical elements of why you should consider shifting to the functional paradigm and why it’s superior.
Functional programming brings clarity. When functions are “pure” — meaning they do not have side-effects — they can be written, tested, reasoned-about and debugged in isolation, without the need to understand external context or history of events surrounding its execution. As ETL pipelines grow in complexity, and as data teams grow in numbers, using methodologies that provide clarity isn’t a luxury, it’s a necessity.
That’s it for this issue, until next time
Did you ever get to the entity-centric modeling post? Really looking forward to that 🙏🏼