
The Data Strategy Playbook - Part 1
Making sense of the data landscape from the outside in
Welcome to the latest issue of the data patterns newsletter. If this is your first one, you’ll find all previous issues in the substack archive.
In the last two editions we started talking about a few data engineering fundamental concepts, like algorithmic complexity and “divide and conquer.” You clearly liked them and I’ll continue to write about them in the future, but in this issue we change our focus a bit.
I’ve been meaning to get into the topic of data strategy for a while now, so I’m planning a series of posts to explore this topic further. Today we’ll talk about the overall data landscape what it means for your career.
Whether you are en entrepreneur looking to build something in the data space, an angel investor or VC looking to invest, or an employee looking for a job, understanding the landscape is key to making smart moves.
And to understand this landscape there’s no better tool I know of than Wardley Maps. I’ve written about this tool in the past and today I wanted to update that post with some of the things I’ve learned since then.
P.S. If you’re curious and want to read my introduction to Wardley Maps you can go here but that’s not necessary for this email.
Wardley Maps 101
There are two core principles of any good strategy:
Situational Awareness: Better situational awareness leads to better strategy.
Gameplay: Strategy is a continuous cycle of moves not a linear plan.
In this post we’re going to focus on developing Situational Awareness about the data space.
Situational awareness is the perception of the elements of a situation, the comprehension of their meaning and their projection into the future.
Adapted from "Designing for Situational Awareness" by Mica Endsely
A Wardley Map has only a handful of key components. They’re easy to grasp but take a lot of practice to master. We only need a quick intuition here so understanding the key components will suffice.
They are:
The Anchor of the map which typically is the user/customer and their needs
The Value Chain axis which indicates the capabilities needed to satisfy customer needs and is represented by the Y axis in the map
The Evolution axis which indicates the evolution of capabilities driven by competition and is represented by the X axis in the map
The Components which are usually capabilities but could also indicate customer needs, data flows, cash flows, etc.
There’s only a handful of things needed to understand the map:
User needs come first. Whether the user is internal or external, their needs come first. This is the most visible part of the value chain.
All the components evolve naturally from Genesis (uncharted territory) to Custom Built to Product/Rental and eventually to Utility / Commodity (widespread). As long as there’s demand and competition, all components will eventually evolve towards utility.
Strategy is not linear, it’s a cycle. Sometimes you need to take action to gain or improve situational awareness then quickly adjust this action in the next iteration.
Let’s take a look at the following map and work our way through it to see if there’s any interesting insights we can gain.
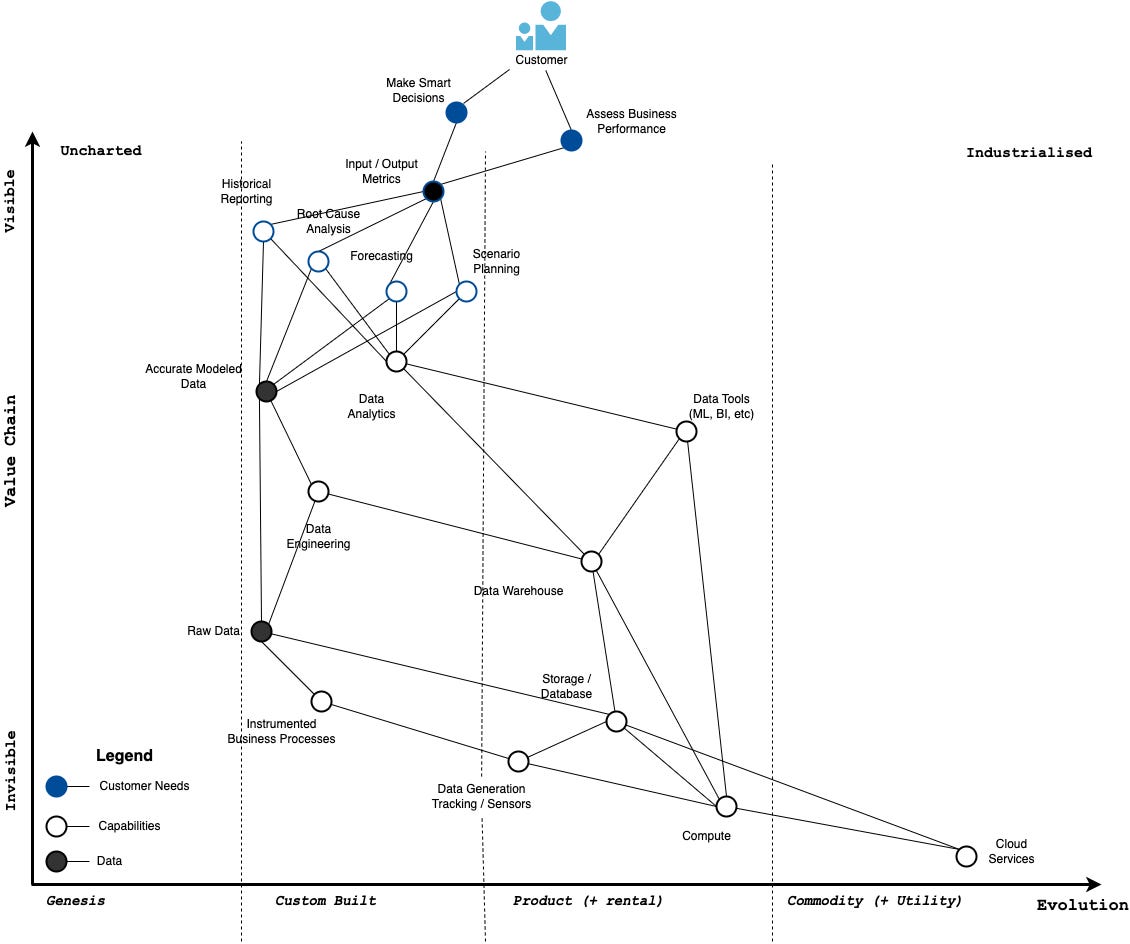
As you can see, the anchor at the top is the user (customer) of analytics. Their needs are represented by the blue circles. We see that what customers need are a way to assess the performance of their business and a way to make good decisions to improve the performance business.
Now let’s trace the chain of capabilities that deliver on these needs. In order to assess the performance of their business and make good decisions they need metrics. There are two kinds of metrics, output metrics that indicate performance and input metrics that enable decision making. Customers need both.
In order to deliver these metrics, we need four capabilities:
Historical Reporting to figure our what happened
Root Cause Analysis to figure out why it happened
Forecasting to predict what will happen
Scenario Planning to figure out what to do next
Currently all of these capabilities exist in the Custom Built stage. Every company builds their own stack from scratch. As I’ve stated before, this is unnecessary and this area is ripe for evolution towards the Product or even Commodity stage.
That’s exactly what I’m working on with the Metrics Playbook (now called SOMA for Standard Operational Metrics and Analytics) You can read more about that here.
In order to deliver the above capabilities you need Accurate Modeled Data which requires Data Engineering and Raw Data. In order to get Raw Data we need to have our business processes well-instrumented with proper tracking put in place.
We also need a Data Analytics capability which requires Data Tools and a Data Warehouse. You can trace the rest of the map the same way, so I won’t bore you with more details there.
Now let’s take a look at some interesting insights we can glean from the map and how it can affect your career or your investments in this space:
Value Chain Visibility
The location of a capability on the Value Chain axis indicates its visibility. Higher on the value chain (towards the user) makes a capability more visible. For example, data engineering is less visible than data analytics/science. This makes it harder to get resources (people, budget) while at the same time making the function more critical.
That’s why I like data engineering as a career choice because it’s so critical to delivering on the user needs and a lot harder to automate. However career growth might be limited.
Accelerating or Blocking Evolution
There are a couple of strategic plays to either accelerate or slow down/block the natural evolution of components. You can accelerate it through open sourcing a product (see dbt core for example). You can stop it through inertia or laws/policies.
This is basically what we’re trying to do with SOMA. By accelerating the evolution of these components towards a commodity, we increase the leverage of analytics teams making them more strategic.
One thing to note here is that if SOMA succeeds, as I certainly hope it does, there’s no longer a need for a very large data team since most of the knowledge will be codified in the standard. This is no different that how finance and accounting work today.
Investing in Data Tools
Creating data tools that support less visible components (lower on the value chain) is relatively easy to do but really hard to sell. Low visibility = low budget. But if you manage to find a wedge and/or create a new component you can have a long lasting moat. Think for example about Snowflake. They managed to wedge themselves into the Data Warehouse component and now are mostly seen as “must have.” I must restate that this is really hard to do.
Building data tools that support the customer needs directly is a lot easier to sell but much harder to actually do. Most BI tools (think Looker, Tableau) try to sell here and have mostly succeeded, however they still require all the underlying data practices be in place to deliver value which limits their moat significantl.
That’s it for now, I’ll write more about this topic because it’s of very high interest to me and I hope to you as well.
Until next time.