
How NCD Saved $330k With Gazer's Modern Analytics Migration
A data architecture case study guest post by Atticus Grinder
Introduction
Welcome to a new issue of Data Patterns. I have a special treat for you this week. With the help of Atticus Grinder we will bring you a case study of a full, end-to-end implementation of a data architecture for a real company. This is not hypothetical or theoretical. This is the real thing.
Atticus is the founder and CEO of Gazer Labs, a data infrastructure and analytics agency specializing in full-stack analytics transformations. He was gracious enough to provide a detailed explanation of the design and modeling of the data stack he implemented at NCD.
Take it away Atticus:
The Case in Brief
For those of you not interested in reading the full implementation, here’s a quick summary:
Before Gazer
Hundreds of hours every month spent on manually pulling data
Regular data failures and inaccuracies requiring manual fixes
Reporting delays and inefficiencies across every vertical
Sales team blind on which levers drove growth
Operations team constantly underwater
Finance team regularly behind in reporting
After Gazer
Centralized ~20 data sources in a single source of truth
Eliminated hundreds hours of manual data pulls and fixes
Created dashboards for sales that unlocked $750K additional ARR and 12k new customers
Saved $330K on analytics resources with a more efficient data platform
Trained entire team on modern analytics stack
Set up auto-testing to ensure accuracy of all data and metrics
Set up proactive monitoring and alerting across the company, to help ops, finance, etc.
80+ hours a week saved leading to a 400% boost in productivity
To contact Gazer directly, email atticus@gazerlabs.com.
The Case in Detail
When we began our engagement with NCD–-an award-winning dental & health insurance company offering white glove service partnering with brands such as MetLife and VSP–-analytics asks weren’t centralized, duplicative work existed across verticals, definitions of key business terms varied, low-code transformation often failed, requiring time-consuming manual fixes.
These issues resulted in the sales team having very poor visibility into their funnel and finance + operations teams reactively responding to changes across the company, often resulting in fire drills and manual reviews.
Across 4 months, Gazer helped NCD:
Stand up a BigQuery warehouse, centralizing ~20 data sources
Develop ELT pipelines using a combination of AWS Fargate and Airbyte
Onboard a dbt-git workflow and upskill a data team of 5 into analytics engineering
Migrate all dashboarding from PowerBI to Omni while securing a 40% annual BI license discount
Set up comprehensive unit testing to ensure accuracy of ingested/transformed data
Set up auto-trigger proactive email alerts for finance and ops teams
This unlocked nearly $750K additional MRR, 12K new customers, and $330K in tech platform/FTE savings.
In this post, I’ll breakdown the technical components and decision making that went into migrating NCD to a modern data stack, across 4 main areas:
ELT/Pipelining
Warehousing/Storage
Transformation
Consumption/BI
NCD Legacy Architecture (before Gazer engagement)
NCD’s primary data source, an insurance policy admin system, contained all their transactional, product, and sales agent data that majority of their analytics/dashboarding depended on. Data was extracted every day, exported to CSV and sent to an SFTP server setup on Amazon EC2. Other third-party data wasn’t ingested or centralized. Users had to navigate directly to the third-party platform and login to pull data manually.
These CSV files were then loaded into Alteryx–which acted as the sole ELT tool–cleaned, transformed and used to generate reports that were sent to external partners. It also loaded data onto a MSSQL data warehouse so they could be queried using PowerBI. Only data in the SFTP was stored in MSSQL, third party data was not integrated.
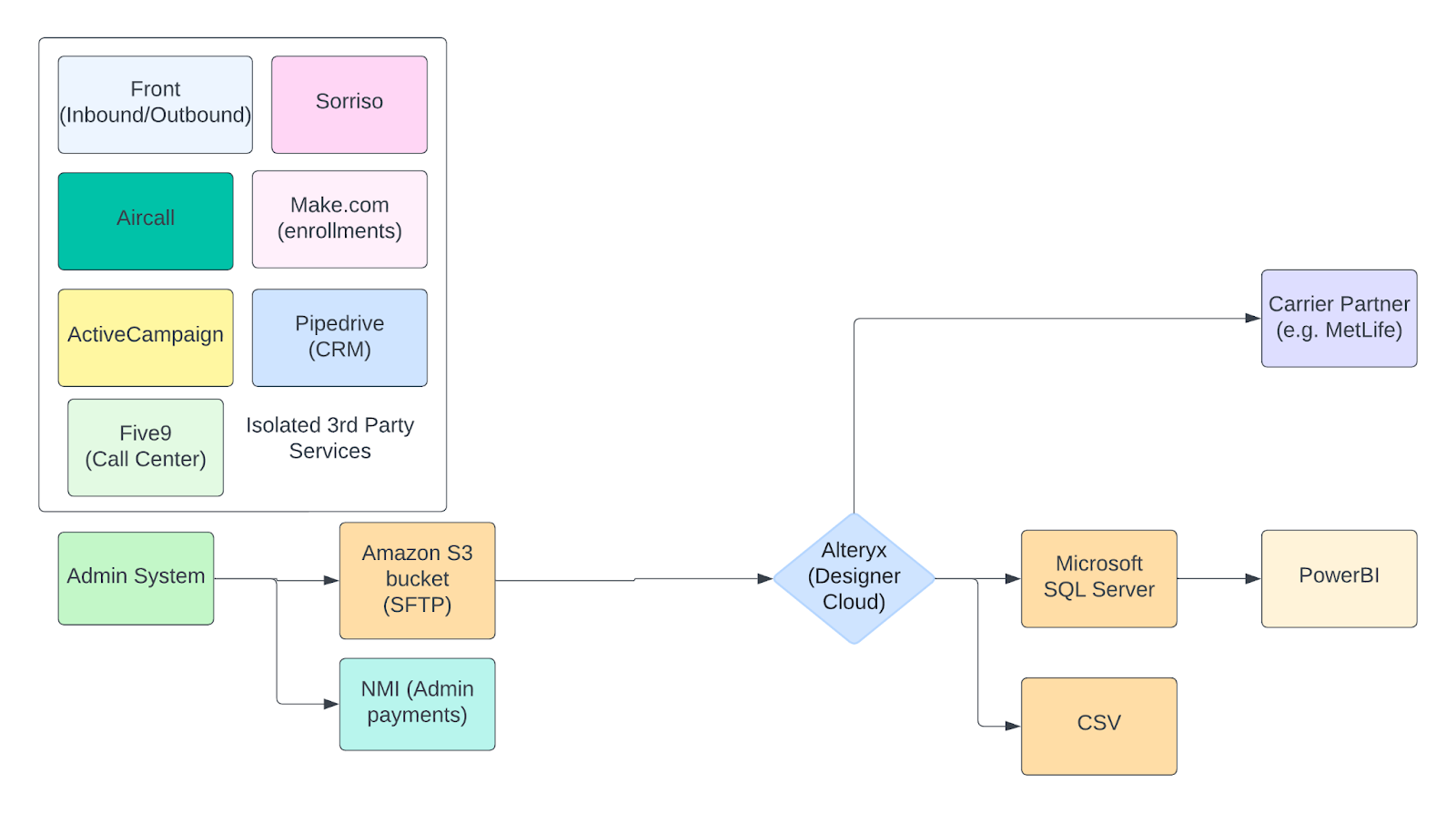
NCD Modern Architecture (after Gazer engagement)
Several improvements were made by migrating architectures. By centralizing first and third-party data sources (e.g. Airtable, NMI) in a single warehouse, we could do transformation on all data sources, and build a cross-functional metrics layer. This also unlocked more holistic analysis (e.g. joining and aggregating customer interaction tables to transaction tables thereby uncovering the effect on sales after a member speaks with customer support).
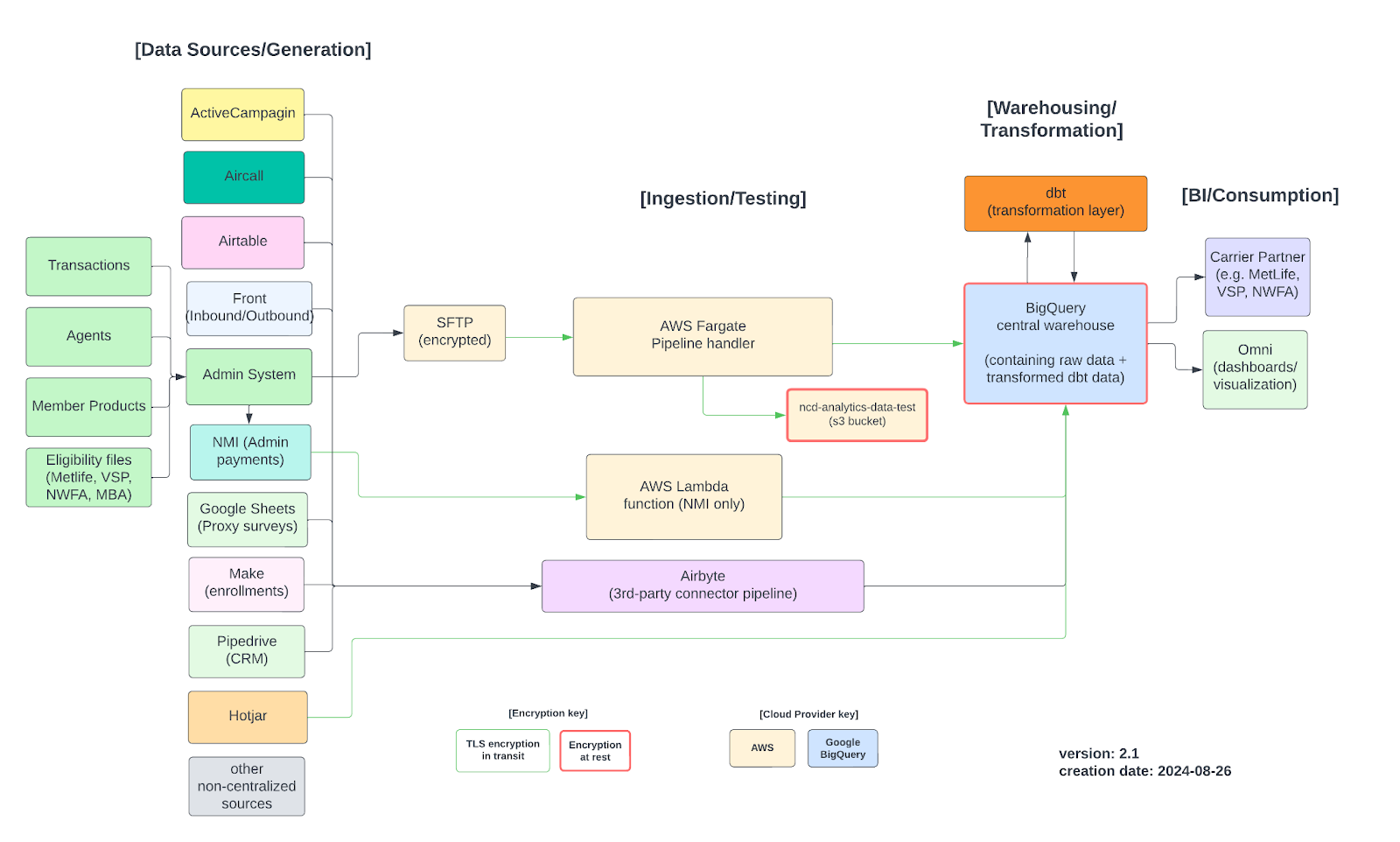
Detailed Data Architecture
ELT Pipeline
We built a new data pipeline for first-party data in python using AWS Fargate. Since NCD’s insurance policy admin system is limited to exporting data via an SFTP server, we had to keep this step of the pipeline. This architecture could be massively improved if the admin system offers an option to load data directly to Google Cloud or S3 buckets in the future. This would make things simpler and easier to maintain.
The AWS Fargate pipeline works by looking for files that exist on the SFTP server which do not have a corresponding ingestion record in BigQuery. When one is identified, it’s retrieved from the SFTP server, lightly transformed then ingested.
We initially built our pipeline using three AWS Lambda functions (emit, ingest, and load), but after hitting consistent SFTP timeout issues when attempting to retrieve the data, we migrated to Fargate. The Fargate setup is scheduled to run once a day at 6AM ET on a cron schedule.
To check pipeline runs, we used AWS Cloudwatch service within the AWS console; but the same can be achieved by querying a watermarks table in BigQuery. This BigQuery table shows the S3 filename, S3 filepath, and pipeline execution time.
All other third-party data was centralized using Airbyte Cloud’s pre-built connectors, or by using Airbyte’s connector builder tool and creating custom API endpoints.
Loading Data into BigQuery
We chose Google BigQuery for building the data warehouse because of its query speed and overall functionality. It lets us easily upload CSVs and Google Sheet data directly to Google Cloud storage buckets and set up tables to be transformed with dbt.
This was useful for manually maintained sheets for survey data, for example. Analysts loved BigQuery’s UI for doing exploratory data analysis with SQL.We also considered Snowflake and Redshift but ultimately went with BigQuery given the overall cost.
We set up a BigQuery database where each primary data source is loaded in its own schema so all its tables are in the same place. Data loaded from the SFTP lives in a schema called s3_staging. Transformed tables live in a schema called dbt. Development branches can be found in a schema called dbt_staging or dbt followed by the last name of the dbt user (e.g. dbt_jsmith).
Transforming Data with dbt
We maintain two layers of tables in dbt:

Base/foundational tables that directly query raw BigQuery tables ingested via pipeline loads in order to clean and transform raw column names and data values. Examples include converting to CamelCase or casting values as integers or strings. This lets us combine multiples source data via a simple UNION ALL like this:
SELECT *
FROM s3_staging.transactions_46580
UNION ALL
SELECT *
FROM s3_staging.transactions_325737Metrics/semantic layer. Our second dbt layer is for metrics. These tables are downstream from raw/base tables and define metrics ultimately used to power dashboards featuring important company metrics and KPIs. These tables query upstream dbt tables rather than raw BigQuery tables. An example of a downstream metrics table may look like this:
{{ config(materialized='table') }}
SELECT *,
CASE WHEN PaymentNumber = 1 THEN 'New' ELSE 'Recurring' END AS BusinessType
FROM {{ ref('transactions_raw') }}We maintain definitions of each column in schema.yml files in dbt. Each model in dbt (under ‘models’) contains its own schema.yml file. Every column and metric is defined here. It’s important for us to stay on top of updating each new change to our data model, otherwise a backlog builds up.

We regularly create + maintain dbt macros for pre-built SQL templates inserted into portions of queries wherever relevant. A common use case for us is a long CASE WHEN statement (e.g. over 10 conditions).

We use dbt tests for unit testing on the column-level to check values of a column. An example could be ensuring a state abbreviation column value is not longer than 2 characters. Tests are applied in the schema.yml file of the relevant model.

We also utilize dbt snapshots for versions dbt tables where output values are compared to previous states. If a row is updated/overwritten with a new value in a column, the snapshot records a timestamp for when the change occurred. Snapshot tables rely on a unique ID to parse records. Sometimes we create unique keys manually by concatenating several column values within a table if one doesn’t exist.
Serving Data With Omni
We migrated all of NCD’s PowerBI dashboards over to Omni, a recently released BI tool (built by the former execs at Looker & Stitch). Omni integrates directly with BigQuery and mirrors all of our warehouse schema.
Omni feels like a dreamy tool pulling all the greatest BI hits into a single platform. It’s super smooth and fun to build with and its feature list runs deep. I feel like it’s reminiscent of Looker circa 2018.
My favorite things about Omni:
There's 2 main pages when building. A 'workbook', containing tabs for each query (like a Chrome browser), where each query maps to a dash visualization. And 'dashboard', where all query charts live. The binary 'flipcard' feel comes up a lot and feels very intuitive. The overall UI brings simplicity to a typically noisy environment without feeling flimsy.
‘Parent controls’ allow you to create a master filter with children filters. Best used for things like toggling between time intervals (day, week, month) across various charts with different underlying time dimensions. This allows dashboards users to filter data in a smoother and more uniform manner.
Each session auto-creates a branch recording manual additions made, such as aggregated measures. if you built a new measure for a query, you can push this as a permanent addition for all other Omni users (and even push to your dbt project).
You can customize which columns you see when drilling down on a specific chart. Drilldown customization exists on the column-level. Meticulous customization is a common theme with Omni.
Tack on columns to SQL output and use Excel functions such as =SUMIFS().
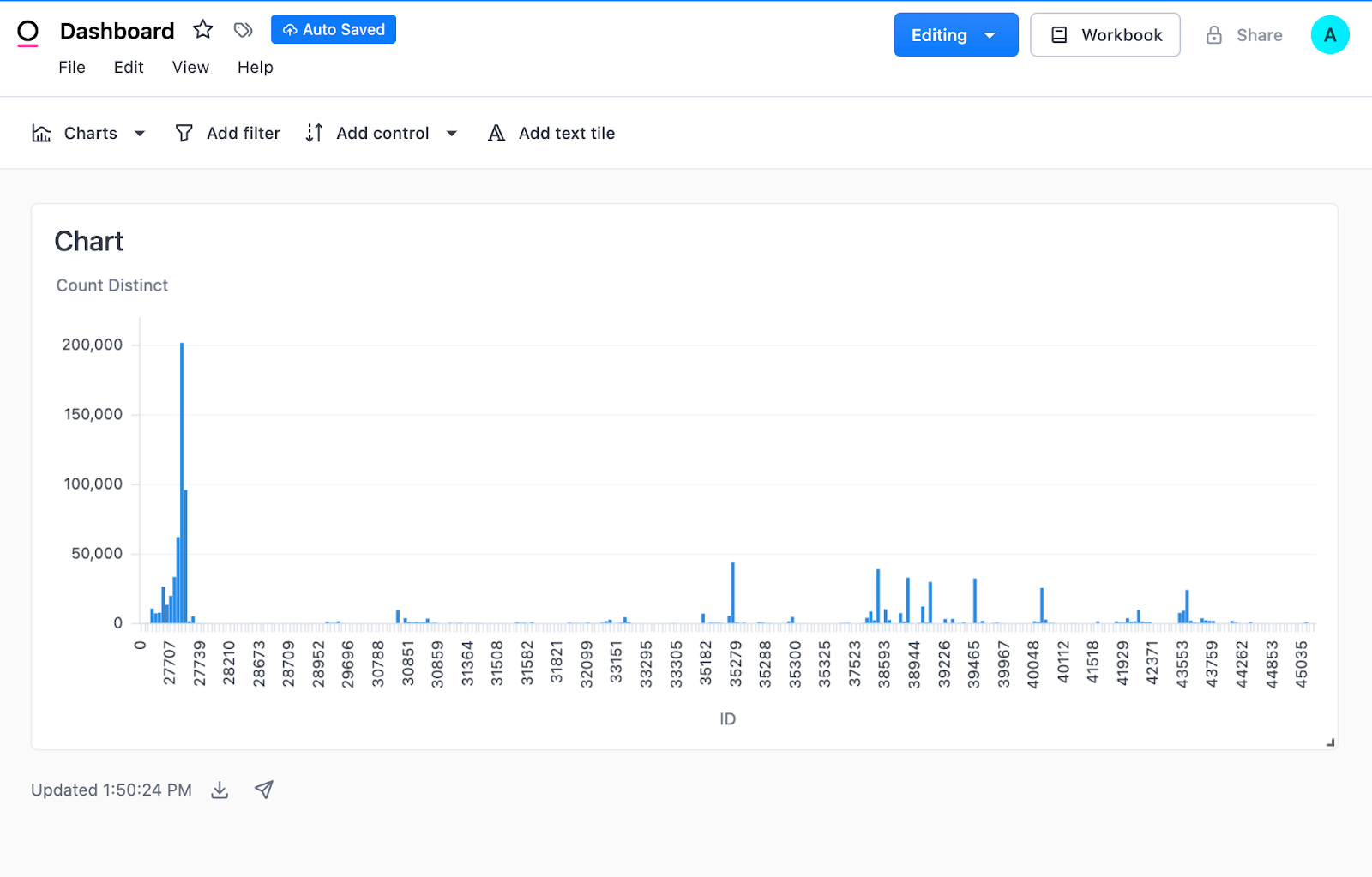
The current options for triggering metric alerts within Omni are based on whether results have changed, stayed the same, no results are returned, or any results are returned. You can adjust how often the alert is run/checked, who the email recipients are, and the content of the email itself (link to dashboard, excel file, PNG of dashboard, etc.)
We maintain ‘Testing’ and ‘Live’ folders to bifurcate dashboard development. All new dashboards (for one or many stakeholders beyond just personal exploratory analysis) begin in the ‘Testing’ folder. Once stakeholders signoff/approve a dashboard, we move them to the ‘Live’ folder.
Migrating NCD’s data architecture was a ton of fun. Bringing a modern workflow to a talented data team and watching them hit the ground running and unlock a ton of value in just a few weeks was a pleasure. It’s great to see so much ROI already come from the engagement.
Wrap Up (by Ergest)
Well I hope you data architecture nerds enjoyed this very detailed post by Atticus. If you want to reach out to him, you can click here. I would like to express my sincere thanks to him for indulging my curiosity and “delving” into the details (No this post was NOT written by ChatGPT)
Until next time
 | A guest post by
|