
Designing Modular Data Workflows
How to apply the Single Responsibility Principle to data engineering
In case you can’t tell, I love modularity.
I’ve written quite a bit about modularizing SQL queries and Kimball dimensional modeling, but I haven’t gotten too deep into the reasons why. In this post I’ll explain what modularity is, why it’s important and how to apply it to your data workflows.
Interested? Ok, let’s get to it.
The Rule of Modularity
When you study computer science and then end up working with data, like I have, you can’t help but see design patterns that are quite prevalent in software engineering applied to the world of data. It was this insight that led me to write my first book, Minimum Viable SQL patterns, which many of you own.
Modularity is one of those patterns that you can’t help but see everywhere, especially in the world of hardware and manufacturing. Everything is made up of components and subassemblies. What’s even more interesting is that many of these components are manufactured by different companies who specialize in just that part.
Seeing this, early software engineers decided to adopt the idea in software design. Early programming languages provided the notion of a “subroutine” that later evolved into the modern concept of a function (or a method if you’ve studied OOP)
Later on they applied modularity to shared standard libraries that are built and maintained separately that you can just import into your code and use without worrying too much about how they work.
UNIX took this idea even further with the development of specialized command line tools that can share both input and output. This way you can take the output of one tool and pipe it into another tool to create complex programs.
Complexity is key here. The only way to write complex programs is to build it out of simple modules connected by well-defined interfaces. This way your program is localized so you can easily fix or optimize parts of it without breaking the whole.
So the key benefit of modularity is to simplify the design and maintenance of complex, interconnected hardware and software systems. If modules are well designed and you can trust them to work properly, you can assemble them in a multitude of ways like Lego bricks.
Modular Decomposition
When it comes to modular decomposition of a system there are a few key principles that apply most of the time. I say “most of the time” because these are not hard rules and it’s up to you to use your best judgement on when to use them.
What we want is to come up with modules that are both easy to build and maintain while also being independent from the rest of the system. This independence is very important because it isolates the modules from impacting the rest of the system and allows them to be designed and tested by separate teams.
From personal experience I can tell you that when you’re building a complex data workflow from scratch, the individual components are not self evident. You will have to refactor your code later if you want to modularize it properly.
Unless you know exactly what you’re building (for example you’re replicating the functionality of an existing system) you won’t know all the modules ahead of time and that’s perfectly fine.
One of the best ways to do modular decomposition is to use the Single Responsibility Principle (SRP). It states that every module you create should have a single responsibility or purpose. Sometimes it’s expressed as every module having a single reason to change which to me is the same thing. The key idea is to separate the concerns so that we can achieve both independence and isolation.
Let’s see if we can build the intuition for this. If you look at your smartphone (iPhone or Android) it’s made up of many components. There’s the touchscreen, the battery, the CPU, Bluetooth chip, WiFi chip, Cameras, RAM, storage, etc. Each of these systems has a single responsibility.
For example the Bluetooth chip provides bluetooth connectivity and that’s it. It has a predefined interface to the CPU so it can be controlled via software; it has an interface to the battery so it can draw power but it doesn’t get involved in providing WiFi connectivity or GPS location. This allows it to be manufactured and tested independently and in isolation.
Applying Modularity to Data Workflows
Ok enough with the preamble, let’s get to specifics. How do you apply the rule of modularity to data?
If you’re building data transformation workflows with SQL dbt-core is a wonderful tool to help you do that. It enables modular SQL through the use of Jinja macros.
I’ve been using it to build the SOMA data model, which I talked about in the last issue of the newsletter. Here’s an example of a macro used to generate the activity fact table. Each of the tables has the same structure and joins the same dimensional tables so to avoid code duplication, we store the shared logic here.

Notice that we’re using another macro inside this macro called `dbt-utils.star()` which allows us to select all the columns from `dimensional_table_ref` except the id. This is the perfect example of modular code. The “star” macro is designed and tested in isolation and as long as I use the proper parameters I don’t have to worry about the implementation details.
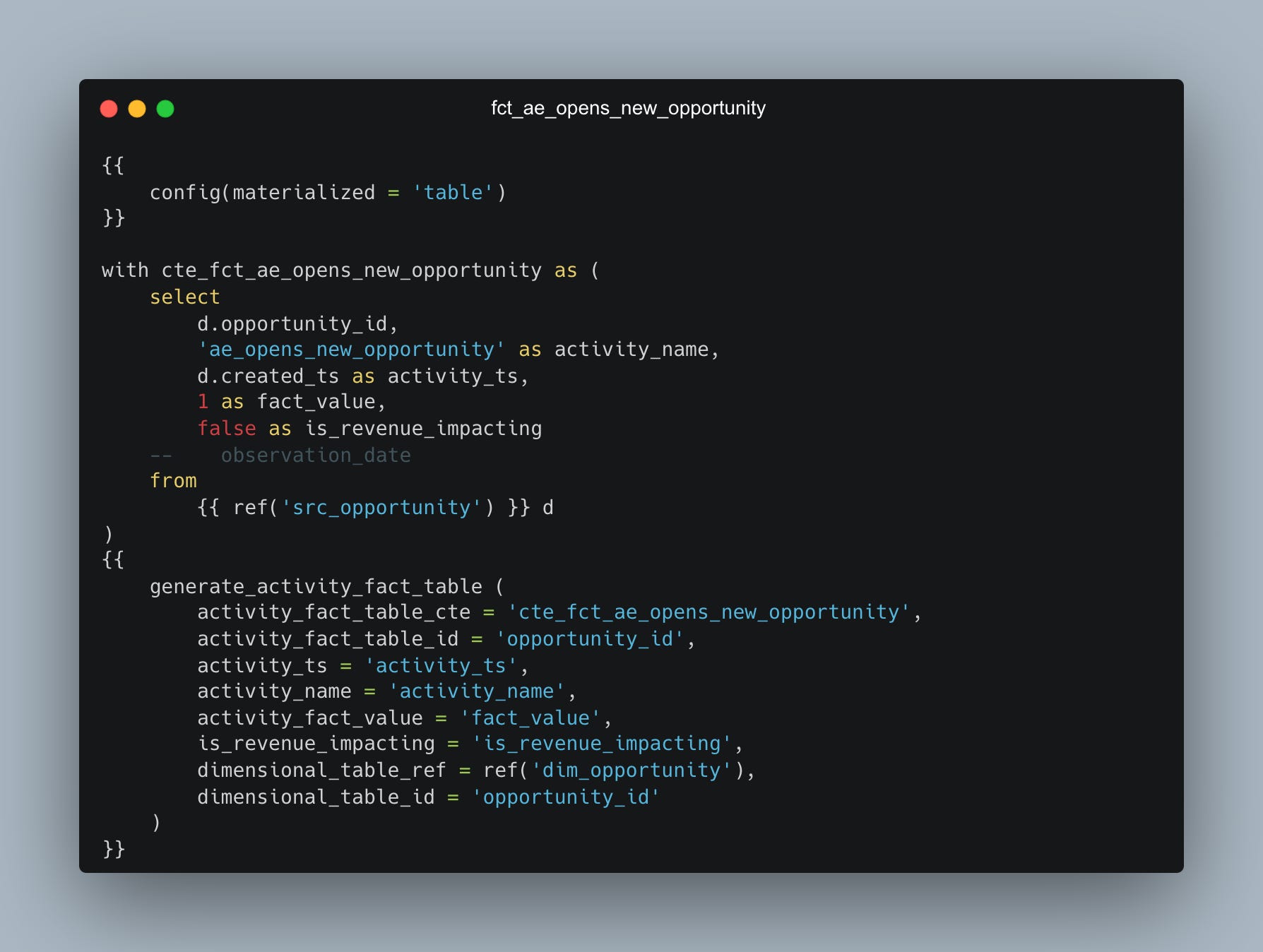
This is how the macro is used to build the activity fact table. Again I don’t have to worry about the specifics of the macro as long as I’ve designed and tested it carefully,
This is just a small sample of how dbt provides the capability for modularizing SQL. I’ll explore this topic more in the future.
Until then.