
Designing an Evolutionary Data Architecture
A journey with dbt and PostgreSQL
Over the last two years I've been building a data workflow with dbt and PostgreSQL. When I started there was only a lightweight architecture in place — what’s known these days as “medallion architecture.” Over time it evolved into a really cool logical design and I learned first-hand what it means to design an evolutionary data architecture.
In this post I’ll cover briefly the history of how that came to be and some of the lessons I’ve learned along the way.
The initial architecture involved having a “bronze” schema in PostgreSQL where we landed raw data as we acquired it. The loading was done via external tools, so I won’t get into that. We then transform it with dbt core to produce a “silver” schema with all the processed data. We don’t have a “gold” schema yet as we’re still building things out.
Here’s a rough diagram of what that looks like:
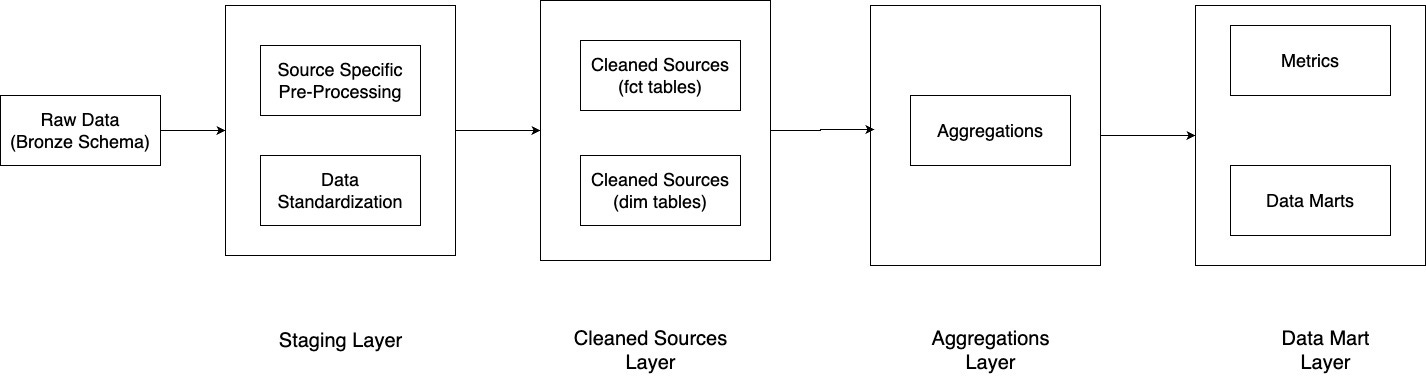
I used to think this was “data architecture” but what I’ve learned is that the concept extends way beyond a simple diagram. It involves figuring out how all the pieces of the system fit together, code design patterns, modularity, testing, observability, etc.
This layered design is one of the key patterns of software architecture but it wasn’t always this pretty. When we started we didn’t even have layers. This design took over a year to finally snap into place. That’s the key behind the idea of evolutionary design, but before we get there we need to cover some basics.
So let’s start at the beginning.
What even is this “Data Architecture?”
Architecture is one of those esoteric terms that conjures up images of complex systems, intricate designs and perfect blueprints. In reality, it's something far simpler.
At its core, data architecture is about breaking down a large system into logical, interdependent parts that work together seamlessly. It's like designing a city – you need to plan how different areas will interact, ensuring that resources flow efficiently and that the overall structure makes sense to both residents and visitors.
On a practical level, data architecture involves organizing assets like tables, views, and user-defined functions (UDFs) in a way that's intuitive and effective. You’re looking to create a structure that someone unfamiliar with the system can navigate easily, understanding the flow and purpose of each component.
At the same time, data architecture also involves making decisions about tools and methodologies (like choosing PostgreSQL vs a cloud data platform), data modeling, system design, coding conventions, documentation, etc. The concept extends beyond the data.
The best architectures are easy to evolve
If there is one lesson you can take from this post it’s this. Unlike real world architectures (buildings, streets, plumbing systems, electrical systems, etc) software architecture is infinitely more malleable. So don’t worry too much about getting the perfect design, especially if you’re building from scratch. You will most likely change it later. If anything, you should strive for a simple design upfront vs anything big and complicated, and constantly refactor it over time.
This is exactly how the journey of our architectural evolution began. Instead of stubbornly sticking to the initial design, we learned to embrace a more flexible approach. The architecture began to evolve organically, shaped by real-world usage and continuous refinement.
We kept applying the same principles on every code review:
Modularizing early and often allowing for easy maintenance and fast development
Adapting the data model to accommodate changing business needs
Implementing constant user and integration testing with dbt for every new model
Documenting conventions as we come up with them
Updating design docs every time it changes by using simple markdown files
Explicitly calling out technical debt and allocate time to fix it during sprints
Continuously updating and refining the architecture based on real world usage
One thing I’m always grateful for is strong technical leadership. To ensure the above principles are applied every time requires leaders who care about clean design, enforce principles on every code review and keep striving for excellence. Without it you get broken windows and graffiti all over your architecture.
The broken windows theory of data architectures
One of the most interesting ideas that applies to data architecture is the broken windows theory:
The broken windows theory states that visible signs of crime, antisocial behavior and civil disorder create an urban environment that encourages further crime and disorder, including serious crimes. The theory suggests that policing methods that target minor crimes, such as vandalism, loitering, public drinking and fare evasion, help to create an atmosphere of order and lawfulness.
Just like small vandalism in urban environments begets more serious crimes, small “vandalisms” in a data warehouse beget unkempt monstrosities.
It’s a sad sight when a well-designed data architecture starts to devolve over time. It’s never obvious at first. A decision to let something slide here, a tiny tech debt incurred here and before you know it, you have an unmaintainable mess on your hands. I’ve seen this happen in a matter of months in a large enough organization.
A clean data architecture is like a well kept garden. If you make sure every new piece is neatly slotted in the right place and you guard against weeds like a hawk, you will pretty much guarantee a clean design for the long term.
That’s it for this week’s. Did you like this post on data architectures? Should I write more? Let me know by liking, commenting or replying.
Until next time.