
Data Analysis Uncertainty Principle
How to separate signal from noise
There are two core principles of data analysis that are key to curating signal:
1. Every data point contains both signal and noise. It's never 100% signal.
2. We can never know the true distribution of signal vs noise.
What do I mean by this? Let’s look at a very simple example.
Below are my book sales per month — since the day I launched it 2+ years ago — across both Gumroad and Amazon Kindle.
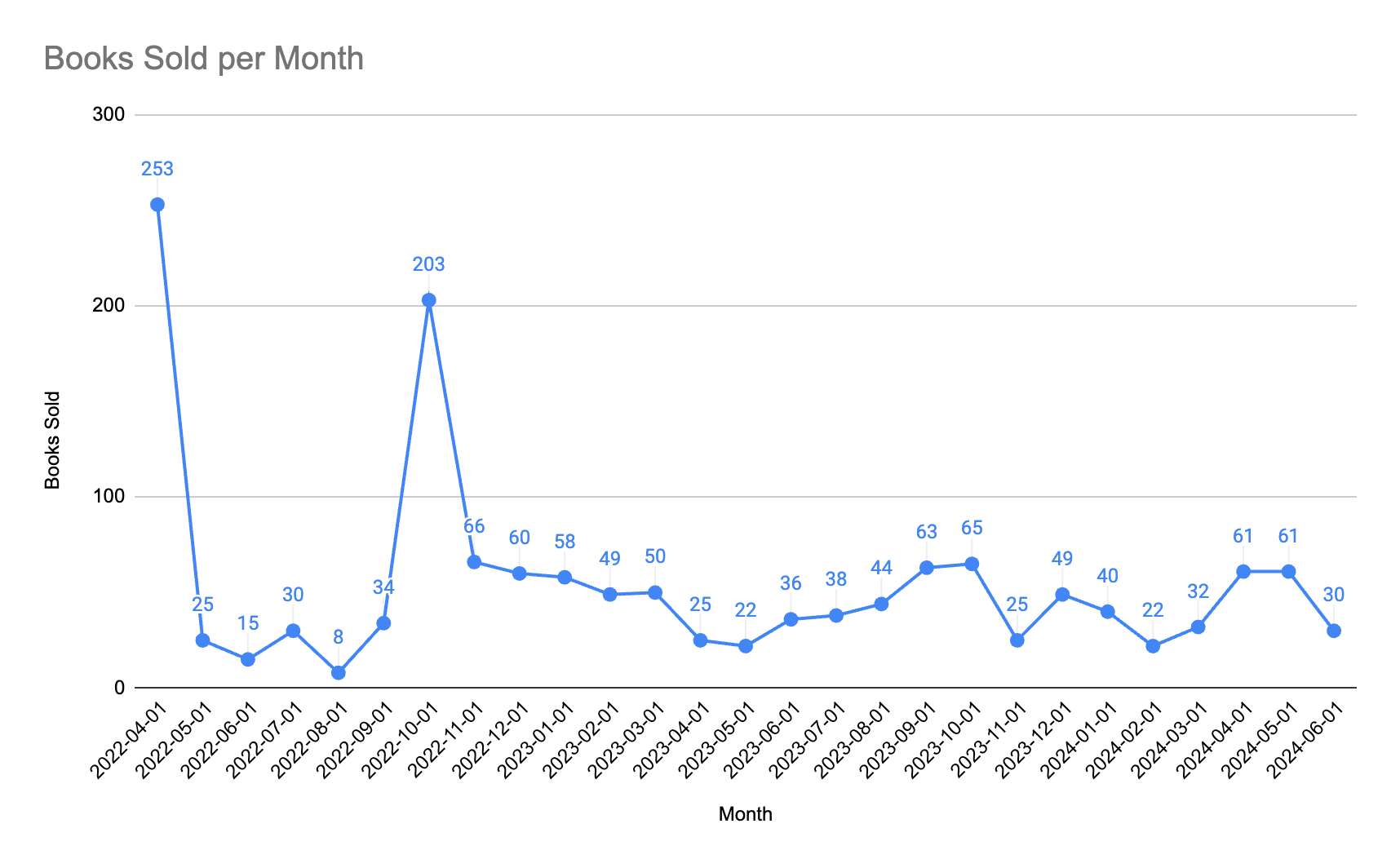
Aside from the two highlights (launch month and one live event where the hosts bought copies for all attendees) I seem to be averaging about 40 copies per month. If you were looking at book sales as a measurement of revenue, there’s no wiggle room there. 61 books were indeed sold in May 2024. That’s a fact.
But if you were looking at book sales as a proxy (signal) for demand, using it to forecast future sales and allocate marketing dollars, things start to get murkier. The fact that I sold 61 copies definitely indicates demand, so we know there’s signal there. But does it mean that demand is exactly 61? That would be foolish to assume.
Does it then make sense to see the drop in sales to 31 in the next month as a drop in demand? Not necessarily. Embedded in the 61 is complex web of factors. Anything from whether I posted more on social media in May vs June, whether I had more posts go viral, whether the algorithm changed, whether the Gumroad page was down, or inaccessible in certain countries, etc.
Many of these factors are unknown and outside my control. And that’s why no data point ever contains 100% signal, especially when it’s used as a proxy for something else. Unfortunately we often treat metrics as if they were entirely signal and then we make key decisions based on that incorrect assumption. Decisions such as “increase marketing spend” or “fix the landing page” or “add more features.”
Wouldn’t it be nice if you knew for sure something was wrong?
Separating signal from noise
When I was a data analyst and I was tasked with analyzing sales, my main goal was to construct a coherent narrative from historical data. Here are some of the ways I would do this:
Compare this month vs last month. In June 2024 I sold 30 copies but the month before I sold 61 copies! Arrgh, that’s terrible right?
Compare this month vs same month last year. In June 2023 I sold 33 copies vs 30 copies in June 2024. Hmm maybe I’m doing so bad, could it be seasonality? Well if you compare last May (22 copies) to this May (61 copies) I’m up by almost 300% Whohoo!
Compare this month to the average. I average about 40 sales a month. Again in June 2024 I sold 30 copies so I’m 25% down while in May I was 25% up. Hmm.
Compare this month to some kind of monthly goal. This is similar to the above.
What’s going on here? Am I doing good or bad? What does it mean?
Since I don’t really promote my book, the sales I get happen when a post on LinkedIn or Twitter gains some traction. People visit my profile, find the link to the book and then decide to purchase it. The posts don’t have to be related to the content of the book, so the stuff I do is kind of random. But should I worry that for example sales dropped by half between May and June?
Yes I want to tell a story with data but which one? Depending on what I was comparing things to the stories were contradictory. In the real world stakeholders would often pick and choose the story that fit their purpose.
I’m trained as a software engineer. In my world there’s truths and non-truths. You can’t pick and choose the narrative that suits you best. So I left data analysis and focused on data engineering. It wasn’t until I read this book called Understanding Variation that things finally clicked into place.
Within every process, no matter how precise, there’s always some variation. Sales go up and down due to a complex web of factors, some within your control some not. This is known as normal variation. As long as you’re within the bounds of normal variation you’re doing fine. It’s only when things change drastically (known as exceptional variation) that you should pay attention.
Believe it not this was already discovered by people much smarter than me almost 100 years ago. Walter Shewhart created some of the first control charts to help improve the quality of products developed at Western Electric Corporation in 1924. We teach masters analytics students all kinds of fancy statistics but don’t teach something as basic as a control chart.
A control chart assumes there’s a variation in any single metric over time and seeks to capture most of that variation (about 90-99%) by calculating the Upper Natural Process Limit (UNPL) and the Lower Natural Process Limit (LNPL) which are based on standard deviation (sigma).
This is what my monthly sales look like with the UNPL and LNPL bars applied

Now that I’ve captured variation, I can use this chart to figure out how to improve sales. I can run various experiments such as buy ads on Twitter, LinkedIn, Reddit; post more regularly on social media, run more regular promotions, do more live events, etc. Each time I can look at this chart and determine if what I did had an impact.
That’s it for this issue. Let me know if you enjoyed it and I’ll write more about control charts in the future.
Until then.
I would propose your June 2022 timeframe was a different mean from post-live-event trends. In SPC, events outside the UCL,LCL typically indicate a shift and therefore a new baseline. Thank you for sharing, love the Control Charts! 😊
You explained this in a simple and intuitive way. Thanks.